When investing the http://schema.org/Book vocabulary, I also had a look at the examples given on that web page. And it turns out they are non-conforming.
Recall that I wrote <meta itemprop="inLanguage" content="en" />English in my book list sample item. The text displayed to the user is ‘English’ and the microdata value, seen by robots, is ‘en’. This difference is necessary since ‘English’ is human-readable, while the microdata field should be a BCP 47 code. As a second example, recall that I wrote <span itemprop="bookFormat">Hardcover</span>. According to the vocabulary, the bookFormat property must be Hardcover, Paperback, or EBook. Hence, if I would like to present a book’s format as ‘PDF’ to the user, I could write <meta itemprop="bookFormat" content="EBook" />PDF.
As demonstrated above, the microdata specification allows the use of <meta> elements as a generic way of specifying user-invisible microdata properties (often next to a user-friendly presentation). [In some cases, there are more specific ways to achieve this, like dates and times, e.g. <time itemprop="something" datetime="2014-11-29">November 29, 2014</time>.]
The problem with the examples at schema.org is that they use a non-conforming way of achieving this (instead of the standard <meta> way). For instance, the following three lines can currently be seen at the Book page at schema.org:
<!-- Wrong! --> <span itemprop="price" content="6.99">$6.99</span> <span itemprop="inLanguage" content="en">English-language</span> <span itemprop="name" content="Tolkien, J. R. R. (John Ronald Reuel)"> J. R. R. Tolkien</span>
Clearly, they use <span> elements with content attributes. This is non-conforming. Neither the HTML5 specification nor the microdata specification even mentions this attribute! (Much less does the microdata specification take this attribute into account when determining the value of a property.) Se this StackOverflow question for more information.
Update (2014-11-29 19:45:57): Of course, a different general way of providing a machine-readable form (possibly a microdata value) of some text is to use the <data> element, as in <data itemprop="inLanguage" value="en">English</data>. This also connects the machine-readable form to the human-friendly form.
The last months I have been considering adding semantic annotation to my web site, but I have not been sure about the choice of technique (microdata, RDFa, or microformats). I eventually chose microdata. (However, I am still not convinced that microdata is the best option.)
Today I added the first microdata to this site. I chose to start by annotating the list of books in my personal ‘library’ using the http://schema.org/Book vocabulary. (My understanding is that schema.org is the de facto first choice of vocabulary. And it is great if we all speak the same language.) So, the old markup,
<ul> [...] <li>Bondy, J.A.; Murty, U.S.R. (2008). Graph Theory. Springer (Graduate Texts in Mathematics), United Kingdom (2010). ISBN 978-1-84628-969-9 (Hardcover) (English) (651 pages)<br/> <em>A very nice, comprehensive, and detailed book on graph theory.</em></li> [...] </ul>
Additional semantics can be added to links (<link>, <a>, <area>) by specifying the type of link. For instance, the footer of my site now explicitly declares that the e-mail address is that of the page author:
Some time ago, I noticed that the horizontal spacing in the TOC was too large in IE7. I didn’t care much about it then, because this was only a minor esthetical issue present only in very old browsers. However, I recently accidently found out the cause of this behaviour. In most modern browsers, the horizontal indentation in a UL (say) is done by the rule padding-left: 40px, and the left margin is zero. Consequently, to change the horizontal indentation (for instance, to remove it), you have only to change padding-left. But IE 7 and below creates the horizontal indentation using margin-left: 30pt instead.
My original CSS was
div#toc ol { list-style-type: none; padding-left: 2em; }
which creates an indent of 2 em in a modern browser, but an indent of 30 pt + 2 em in IE7 and below. When I realised this, I changed the CSS to
div#toc ol { list-style-type: none; padding-left: 2em; margin-left: 0em; /* Old IE */ }
In fact, I do not know of any specification saying that the left margin must be implemented using padding, so it was a bit thoughtless of me not to consider the margin in the first place.
In the same article, I also noticed that the TOC spacing problem worsened in IE6. The reason is that the + selector doesn’t work in IE6, so the following style is ignored:
div#toc>ol { padding: 0; margin: 0; }
See the change in IE7 on Windows Vista: Before and after.
Update (2014-11-21): Well, the HTML5 specification suggests that padding-left: 40px be used for lists (OL, UL).
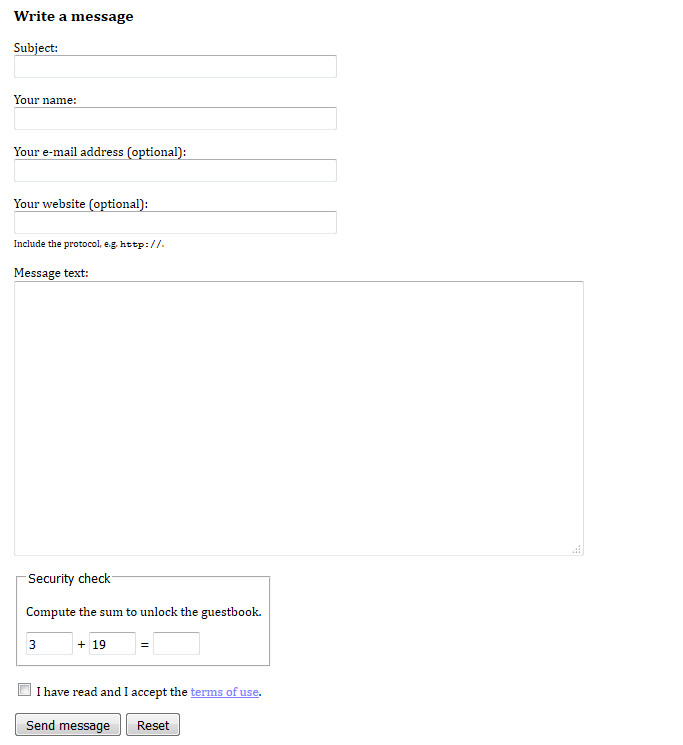
<ul> <li>Also include the website protocol (most often <code>http://</code>). (The <code>mailto:</code> e-mail protocol is understood and should not be entered.)</li> <li>By submitting a message you accept the "<a href="gb_rules.asp">terms of use</a>".</li> </ul>
<p><strong>Security check</strong><br />Enter the sum to unlock the questbook!<br /> <input type="text" name="security1" readonly="readonly" value="16" /> <input type="text" name="security2" readonly="readonly" value="26" /> <input type="text" name="security3" /> </p>
<p> <input id="InputAcceptRules" type="checkbox" name="fAcceptRules" value="yes" required="required" /> <label for="InputAcceptRules">I have read and I accept the <a href="gb_rules.asp" target="_blank">terms of use</a>.</label> </p>
The entire section is wrapped inside a semantic <section> element.
The form controls no longer have the very WET and (inappropriately) inline style attributes.
The labels are marked up using the <label> element. Besides being more semantic in general, this also gives the labels a different behaviour in a visual browser.
The inappropriate use of <br> is removed; instead each ‘line’ is a paragraph. The default rendering of this markup would put the text fields to the right of the labels (in an unaligned fashion), but I use CSS to fix that.
The ‘security check’ is wrapped inside a <fieldset> element with a <legend>.
The sizes of the input fields are specified.
I use specific types of input controls depending on the kind of data format expected: type=email and type=url. This will help the user agent give relevant autocomplete suggestions, display the appropriate on-screen keyboard, and validate the form before it is submitted.
The mandatory fields are marked up using the required attribute to enable user-friendly client-side validation (done automatically by the user agent).
The security3 element has autocomplete turned off, since previous values are irrelevant.
The security3 element has a custom validation requirement. If an incorrect value is entered by the user, the user agent will display the specified error message in an appropriate fashion.
The optional fields are now clearly marked as optional.
The hint about the protocol in the website field is now given next to the input field itself. It is marked up using the <small> element, as suggested in the HTML5 specification.
The link to the terms of use has been made into a checkbox, which is common practice. Hence, I no longer need the UL that I previously used. Instead, information is given where it is needed.
In order to style this, a very small piece of CSS is needed:
Indeed, I clearly want text fields and similar controls to be positioned below their labels, but I do want checkboxes and radio buttons, which precede their labels, to remain inline.
The second rule is needed to reduce the width of the fieldset.
Notice that labels, fieldsets, and legends are not new to HTML5 (and neither is good general design). On the other hand, the new types of input controls (type=email and type=url), the autocomplete attribute, and client-side validation are HTML5 additions.
The markup is dreadful! Although the problems are obvious, here they are:
Since the list of documents is ... well ... an unordered list, the <ul> element should probably be used.
A table should only be used to mark up tabular data!
singleBorder, limWidth, and left are about presentation; classes should be about content.
The non-breaking space is used to create a visual distance. First, content should not be used to alter the presentation. Second, the non-breaking space is most definitely not supposed to be used like this!
The metadata isn't marked up properly.
Clearly, this ancient markup had to be improved, and yesterday I changed it to
Initially, my plan was to recreate the original style, but halfway through the process of writing the CSS I discovered that the current partial result actually looked better than the original design, so I decided to divert from my plan; instead, I added some visual candy to the intermediate result. The end result looks much more modern and clean.
Unfortunately, there appears to be a ‘bug’ in IE 6 and below which creates a ‘staircase’ going into the left margin of the page; see a minimal example demonstrating the issue. I ‘solved’ the issue by adding an IE 6-and-below stylesheet with
ul.documentList li { padding: 0px; /* To work around an IE 6 bug */ }
Update (2014-11-17 19:28:42): I changed padding: 0px to boder: none. Both make the staircase disappear and the padding is more important than the border.
The markup of a general article on this site is now almost perfect:
<article id="ITEM170"> <header> <h2>Boktips: <cite>Svenska skrivregler</cite> från Språkrådet</h2> <dl class="metadata" lang="sv"> <dt>Notis</dt> <dd><a href="article.asp?ItemIndex=170">170</a></dd> <dt>Datum</dt> <dd><time>2013-10-18</time></dd> </dl> </header> <p>Det var med skräckblandad förtjusning [...]</p> </article>
(This is from the Swedish site, so <html> has lang=sv.) Notice the use of the <time> element to mark up the date. Since the date string is already machine-readable (in one of the formats given in the HTML5 specification), there is no need for the datetime attribute. The CSS and the rendering is shown below.
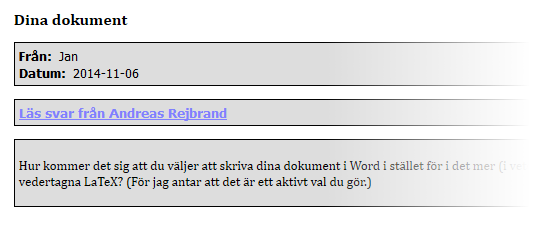
<div> <a href="gb_response.asp?MessageIndex=343">Läs svar från Andreas Rejbrand</a> </div>
</header>
<div class="messageText"> <p>Hur kommer det sig att du väljer att skriva dina dokument i Word [...]</p> </div> </article>
The rendering of this new semantic markup should match the original style of my guestbook, as shown in the following screenshot.
Here I use a special class to indicate that this is not a standard ‘article’ but a guestbook message. And obviously, a special class is needed in order to style guestbook messages differently from the standard ‘articles’. The new CSS is
article.guestbookMessage header div a { font-weight: bold; }
I clearly need the inherit value, because I want the header to be transparent (and, indeed, the parent element is not guaranteed to be black text on white background). But this gave rise to a minor problem, because this CSS value is not supported (at least not properly) in IE 7 and below. The solution is simple enough, however. I simply added the following code to my IE7-and-below stylesheet:
This assumes that the parent indeed has black text on a white background, but this is the case if the default stylesheet is used, and alternate stylesheets are not supported in IE 7 and below anyway.
Although it was mainly a trivial exercise to upgrade to the HTML5 doctype and start using the new semantic elements, some additional effort was required in order to maintain compatibility with old user agents. Indeed, Internet Explorer 8 and below will simply ignore these elements when constructing the DOM. This is a problem, in particular, if you want to style them. Fortunately, there is a very simple way of making Internet Explorer 5.5–8 keep these elements. The trick is to create ‘samples’ of them using JavaScript. In my case, I added
to the HEAD section where the contents of html5.js is simply
/* Make HTML5 elements accessible to IE 5.5 - IE 8. */ document.createElement("header"); document.createElement("nav"); document.createElement("main"); document.createElement("article"); document.createElement("footer"); document.createElement("aside");
This will make the new elements appear in the DOM as expected, but they will be given a ‘default’ style of display: inline instead of the expected display: block. Therefore I also added
to my global CSS file. This CSS is also required by other pre-HTML5 browsers that do create the expected DOM but – of course – do not know that the unknown elements should be ‘blocks’.
HTML5 became a W3C recommendation last week (28 October 2014). Therefore I have now changed the doctype of my main websites from XHTML 1.0 Strict to HTML5. Since I have been thinking in terms of the HTML5 semantics a long time, only very minor changes had to be made in order to make the pages make full use of the new language. Besides changing the doctype, I have performed substitutions such as <div id="footer"> to <footer>. Indeed, the main benefit of the new doctype is that I can use the new HTML5 semantic elements, such as <header>, <footer>, <main>, <nav>, and <article>, to make the markup more semantic. For instance, consider the main layout of a typical web page on this site:
(Recall that each article header contains a heading and a metadata name–value DL.)
Of course, HTML5 has many more benefits in addition to the semantic elements listed above. For instance, I can now use the <video> element to embed videos. I have actually already done so for quite some time on a small number of pages, but not until now will pages with such content validate.
While studying web standards and improving the markup of my own sites, I noted that the <di> element from XHTML 2.0 would be practical. In particular, it would make it much simpler to style metadata name–value lists that are semantically marked up using HTML5 description lists using currently-available CSS selectors and properties. I wrote a letter to Ian Hickson (the WHATWG HTML5 editor) about this. Already before I had received his reply, I realised how bad it sounds to ask for HTML changes to simplify styling, but in my defence, the DI element in itself has nothing to do with styling, and makes sense semantically (although it is superfluous). Naturally, Mr Hickson pointed this out in his reply, but he also informed me about the run-in value for the CSS display property, which I was not aware of. And, as it turns out, this is in fact perfect for my needs.
From the W3C (see below):
A run-in box behaves as follows:
If the run-in box contains a block box, the run-in box becomes a block box.
If a sibling block box (that does not float and is not absolutely positioned) follows the run-in box, the run-in box becomes the first inline box of the block box. A run-in cannot run in to a block that already starts with a run-in or that itself is a run-in.
Otherwise, the run-in box becomes a block box.
The example given in the spec. is about an H3 entering the paragraph following it. Consequently, using this value on DT elements (each followed by a DD element, like in a metadata name–value list) is very natural, and much more appropriate than using float.
run-in is a somewhat lesser known value, and it appears like it is only mentioned in the CSS basic box model Working Draft from August 2007. Turning to browser support, it is remarkably good in Internet Explorer, which supports run-in already in IE8. Google Chrome and Safari supports it as well. However, not even the latest version of Firefox supports this value.
As an example, consider the following hypertext document:
Update (2013-10-17 21:44:33): I just saw that the W3C document has a current version.
Update (2014-03-24 22:15:55): A month ago, I noticed that Google Chrome no longer implements run-in. Therefore, I suppose we will not see any universal support for this value any time soon.
Compatibility with old user agents is very important to me, because I strongly believe that if you buy a computer at any time, and it works perfectly, then you should be able to stick to that computer for as long as you wish. After all, a writer who bought a high-quality computer in the late 90s should still be able to use it the exact same way he did when it was new. In addition, if you do separate content (HTML) from style (CSS) as you should do, it should not be particularly difficult to ensure a decent fallback on old user agents.
Before the recent markup improvement on my sites, they were essentially compatible with every version of Internet Explorer from 5.0. The new markup, which is far more elegant, efficient, and modern, requires only little more: Internet Explorer 5.5. Hence, my sites remain very compatible in this respect. As a comparison, some of the most visited sites on the web fail already in Internet Explorer 6.0 on Windows XP (microsoft.com being one example).
At my sites, almost no JavaScript is used; I almost exclusively work with hypertext documents (as apposed to hypertext applications), and I strongly believe that hypertext documents should only be declarative if possible. Therefore, the main issue in terms of legacy browser compatibility is the CSS support. At the MSDN, Microsoft provides a comprehensive description of the CSS support in old versions of Internet Explorer. Below is the subset of this data that is of significance to my sites:
Feature
IE 5.5
IE 6
IE 7
IE 8
IE 9
IE 10
text-shadow
No
No
No
No
No
Yes
box-shadow
No
No
No
No
Yes
Yes
:last-child
No
No
No
No
Yes
Yes
:not
No
No
No
No
Yes
Yes
:lang
No
No
No
Yes
Yes
Yes
:before, :after, content
No
No
No
Yes
Yes
Yes
+, >, ~ selectors
No
No
Yes
Yes
Yes
Yes
Attribute selectors
No
No
Yes
Yes
Yes
Yes
linear-gradient
No
No
No
No
No
Yes
-ms-filter
No
No
No
Yes
Yes
Yes
filter
Yes
Yes
Yes
Yes
Yes
Yes
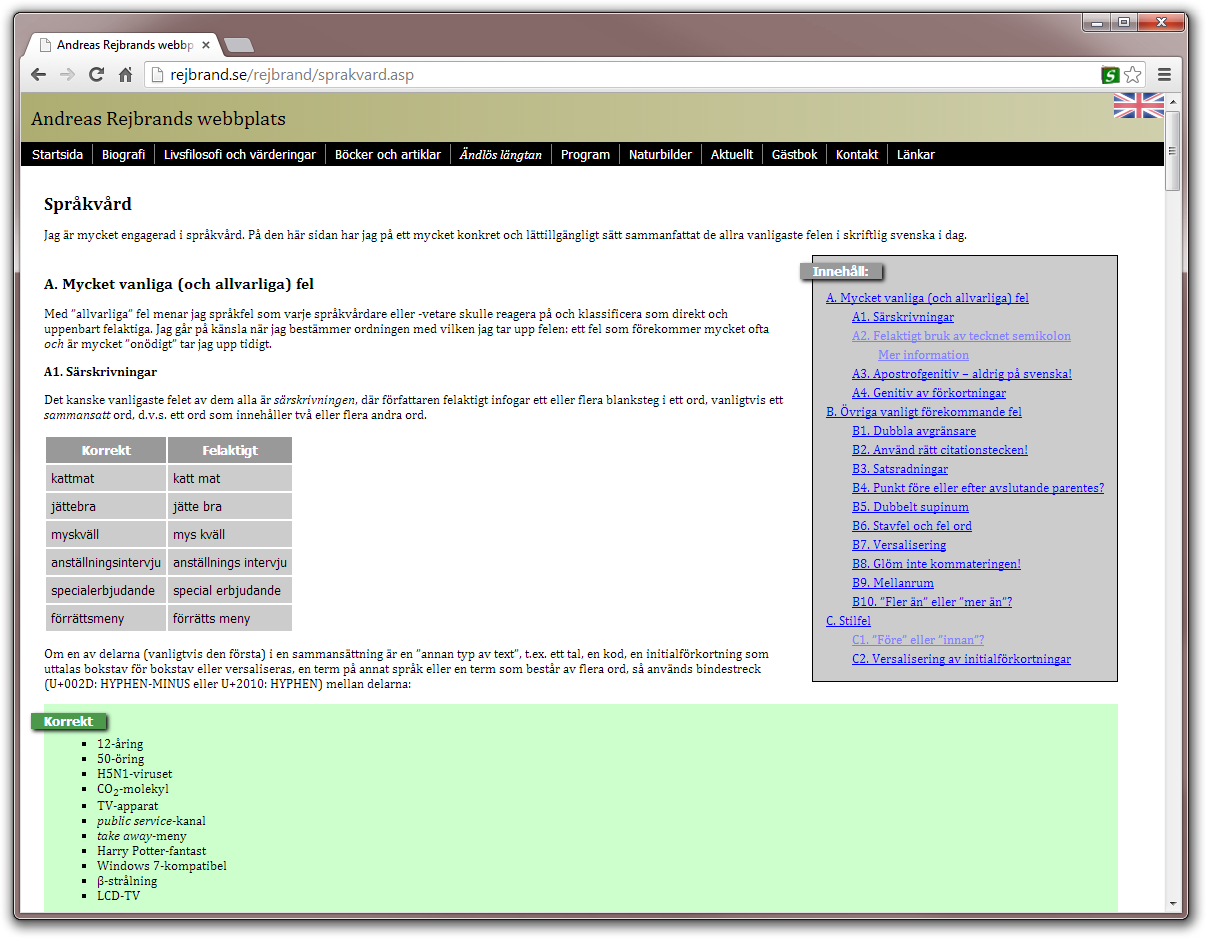
I have every (non-current) version of Internet Explorer from 3.0 and upwards installed in virtual machines. Below, I give the details of the rendering of my sites in all these versions of Internet Explorer. I investigate only my article on Swedish grammar since that page is the most technically demanding page on the site; it even includes a JavaScript that automatically generates a TOC.
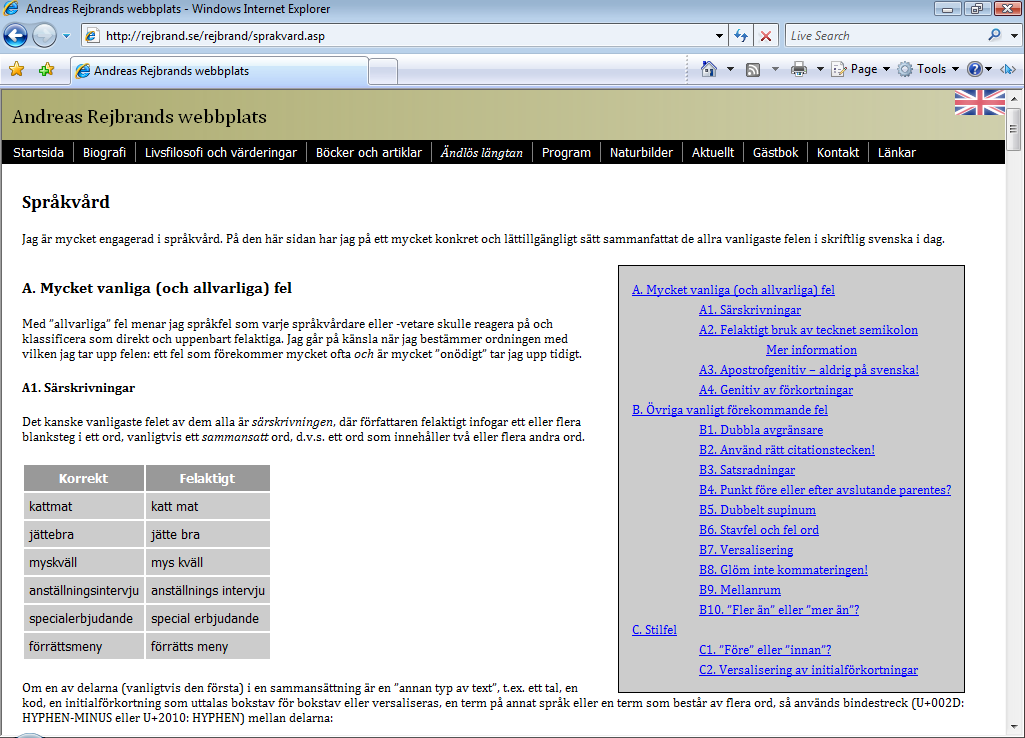
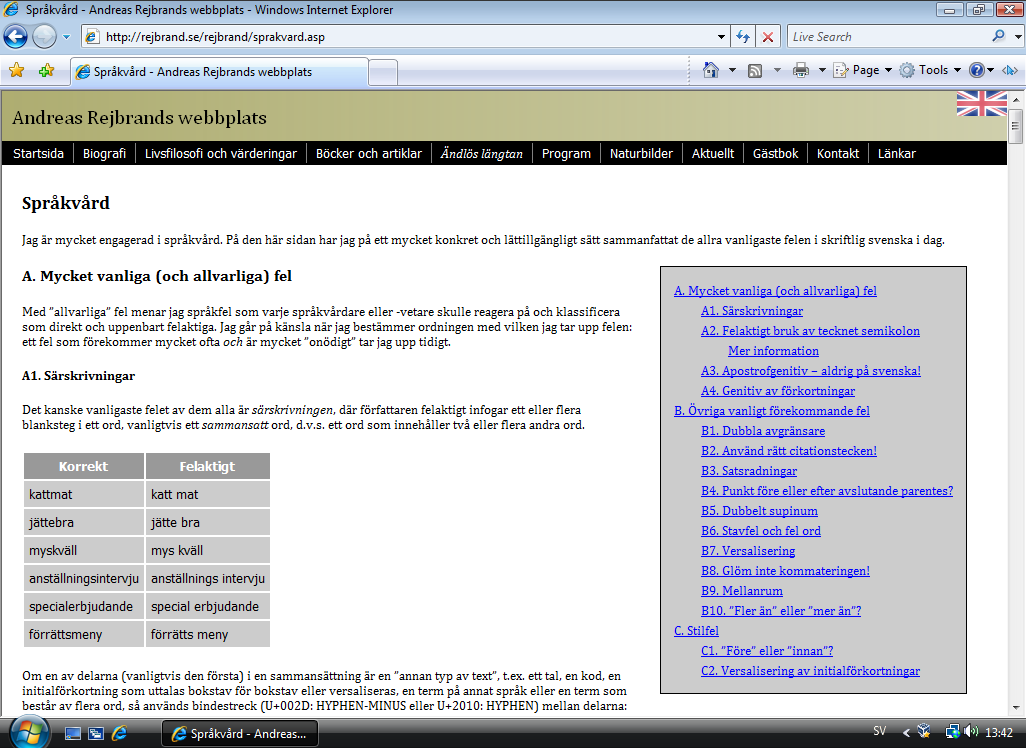
Internet Explorer 10 is the most recent (stable) version of Internet Explorer, and this produce the reference rendering of the page. Of course, the page looks exactly the same in any modern browser (Chrome, Firefox, Safari, Opera). See screenshot. In Internet Explorer 9, we lose support for the text-shadow property, which is used as a special effect when hovering the logo at the upper-left part of the page. It cannot be stressed enough how unimportant that feature is; hence, essentially, my site looks perfect even in IE9. It is interesting to notice, however, that the square bullet (in a UL, say) has a very distinctive look in IE9. See screenshot. Turning to Internet Explorer 8, we lose box-shadow, as apparent in the screenshot from Windows XP. We also lose the :last-child and :not selectors used in the pixlinks (see below). Moving on to Internet Explorer 7, we lose CSS generated content (:before, :after, and content) and, at the same time, :lang(). At my sites, a link on a page in Swedish to a page in English is marked with the flag of the United Kingdom, and similarly the other way around. These are added using CSS content, the language selector, and attribute selectors testing the hreflang attribute on the anchor element. Also, an article in one language, found on a page in the other language, display a flag in the header. This is also done using CSS generated content and the language selector. Apparently, these features are lost in IE 7. Screenshot from Windows Vista.
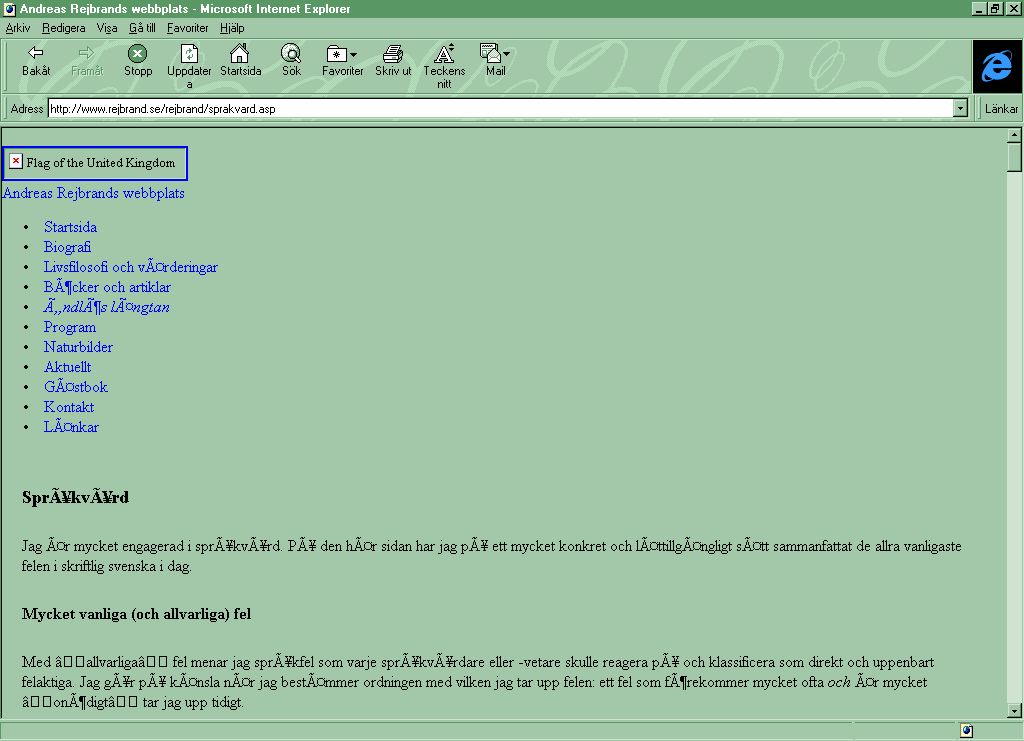
In Internet Explorer 6, the attribute selectors are gone, but that doesn't affect me much, since I mainly use them together with the language selector and CSS generated content, which were lost already in IE7. Much worse is the lack of support for the + selector; now there is no longer a border between the items in the navbar, as apparent in the screenshot from Windows XP. Also notice the strange left margin in the TOC. In Internet Explorer 5.5, some more CSS problems arise. See the screenshot from Windows 95. But if you only ignore these (fairly minor) visual imperfections, the site is still very readable. Even the JavaScript TOC generator works perfectly.
Internet Explorer 5.5 is the oldest version supported. However, the horror is not particularly severe when you turn to Internet Explorer 5. In this screenshot from Windows 95, it is apparent that most parts are still perfectly readable. The navbar styling is now very poor, however, and the TOC doesn't look good either. Since most pages do not have a TOC, it is the new semantic navbar that made me stop supporting Internet Explorer 5. Moreover, at least on my virtual system, many (Unicode) font glyphs are missing. Turning to Internet Explorer 4.0, things get much worse. As seen in the screenshot, basic CSS positioning fails (the flag is not at the right side of the page any more), and the navbar is no longer horisontal. In addition, the TOC JavaScript fails. We end this journey with Internet Explorer 3 which fails rather badly. In the screenshot it seems like most CSS is ignored, there is no PNG support, all non-ASCII characters are displayed incorrectly, and all sorts of things go wrong. Still, with some effort, the page is readable (although it might actually be easier to read the text in the HTML source code, at least if you have access to a UTF-8-aware editor).
Perhaps the most thrilling observation of them all, however, is that the vector linear gradient in the logobar works all the way down to Internet Explorer 5.5.
A few days ago, I observed that the latest version of the HTML5.1 Editor's Draft has changed the meaning of the cite element: now it is allowed for many more things than just titles of works. The only requirement is that the contents of the element is a reference to a 'creative work' (in a very broad sense) and contains at least the title of the work, the author, or a URL. The contents can be of any form. I am not really fond of this change, since the previous version was much easier to use right and it had a very precise meaning. (It also was very useful in practice, since you generally do need some markup for titles because you generally want them in italics.) However, since the new version is a superset of the old one, in the sense that every valid use of cite according to the previous version is also valid according to the new version, this doesn't effect me, so I won't complain: I can still use the element the way I want to, and it is conforming.
Actually, I had the great privilege of discussing the matter directly with Steve Faulkner, one of the W3C HTML5 editors.
Yesterday I wrote about the improved markup on my sites. Although I didn’t mention it explicitly, it almost goes without saying that almost all my webpages are now conforming to the W3C HTML and CSS3 specifications. Although I think in terms of HTML5 and use the HTML5 semantics in most cases, the doctype is still XHTML 1.0 Strict. Now, on one single page, I do actually use the HTML5 <video> tag. Of course, this makes that page a non-conforming XHTML 1.0 Strict document, but in practice there is no problem at all: every HTML5-aware browser I know of will display the video just fine, as if the doctype was the HTML5 one. I will soon upgrade to the HTML5 doctype, and then 100 % of my webpages will be standards-compliant.
It is somewhat interesting to examine the standard compliance of external major websites. It turns out that many, if not most, actually are non-conforming. Here are a few examples:
Website
Doctype
HTML status
CSS status
rejbrand.se
XHTML 1.0 Strict
Valid
Valid
svt.se
HTML5
Invalid (not far from valid)
Invalid
datormagazin.se
HTML 4.01 Transitional
Invalid
Invalid
bbc.co.uk
XHTML + RDFa
Valid
Invalid
microsoft.com
HTML5
Invalid
Invalid
apple.com
HTML5
Invalid (not far from valid)
Invalid
adlibris.se
HTML5
Invalid
Invalid
google.com
HTML5
Invalid
Invalid
w3.org
XHTML 1.0 Strict
Valid
Valid
In most cases, I have examined only the main page of the site. I suppose most big sites use frameworks making each page comparable to each other page in terms of overall markup and page layout.
As I wrote a few days ago, I have been studying web standards rather intensely during my recreational time this summer, and I have used my new knowledge to improve my web sites. In this article, I’d like to discuss the main improvements.
First, you should notice that most improvements are invisible to the outcome of rendering the HTML in a browser; instead, most improvements are related to the semantics and cleanness of the markup. By ‘cleanness’, I mean that all parts of the markup related to styling the document has been removed to CSS stylesheets. Nevertheless, there have been a small number of visual improvements.
Now, let’s dive into the details. First, as I wrote, I have separated contents (HTML markup) and presentational information (CSS stylesheets) perfectly. Now the HTML markup only contains the information of the document, and makes absolutely no assumptions about the way the document should, can, or may be styled. Actually, my sites were rather good in this respect already before this work began, but I have removed a number of <p> </p> previously used to add vertical space. Now this is done using CSS margins.
Turning to the general structure of each page, I have been thinking in terms of the HTML5 semantics. Hence, each document consists of DIVs with different IDs: header, toolbar, mainContents, and footer. When the time comes and I move to the HTML5 doctype, I might change these to the new semantic HTML5 elements (<header>, <nav>, <main>, <footer>). Previously I used classes instead of IDs for these DIVs. The new use of IDs feels more appropriate since these elements occur exactly once per page. Notice that the ID toolbar of the main navigation bar is a leftover from the very first version of my current site design from the early 2000s. This strange ID will (obviously) vanish when I upgrade to the HTML5 elements.
First, notice that the separator character, which was purely presentational, has been removed from the markup, as required by the principles. Also notice the semantic use of the unordered list. Notice that the classes on the links have been removed. This is because I don’t want to repeat myself (DRY); it is already apparent that the links are toolbar (navbar) links, because they are children of the div#toolbar node in the DOM tree. All the fancy CSS selectors are there to be used! This removal of unnecessary classes in this way has been done in many places. The CSS related to the navbar is
#toolbar { color: #FFFFFF; background-color: #000000; padding: 0; } #toolbar ul { list-style-type: none; margin: 0; padding: 0; background: black; color: white; padding: 2px; font-size: 0px; } #toolbar li { background: black; display: inline; /* If 'inline-block' is not recognised, like in FF 2 */ display: inline-block; margin: 0; padding: 2px 4px; font-size: small; } #toolbar li + li { border-left: 1px solid gray; } #toolbar a { text-decoration: none; padding: 2px 5px; } #toolbar a:link, #toolbar a:visited { color: white; background: black; } #toolbar a:hover { color: black; background: #CFCFAC; } #toolbar a:active { color: black; background: #AEAD71; }
I considered using CSS content to add a vertical line character (|,U+007C: VERTICAL LINE) between the items in the list, but eventually settled for the border approach instead; it looks somewhat better, actually. Since display: inline-block is recognised in IE 7 and some earlier versions, but ignored on elements that are block-level by default, I use an IE conditional comment <!--[if lte IE 7]> to include the following CSS file:
/* This is not a valid CSS stylesheet. However, it conforms to a data format expected by Internet Explorer 7 and earlier. */ /* This file must not be used by a valid HTML document. Of course, it may be 'linked' inside a HTML comment. */
#toolbar li { display: inline; /* IE ≤7 recognises 'inline-block' but doesn't render it correctly for LIs. */ }
Oh, this reminds me of an improvement of the logobar (webpage header). Previously, the logobar consisted of a raster image with the text “Andreas Rejbrand’s Website” on a linear-gradient background. Of course, that sucks! Both text and linear gradients should be done by ‘vector’ means. Now, the markup is simply
<div id="logobar"> <a href="default.asp"> Andreas Rejbrand's Website </a> </div>
Yes, I couldn’t help adding some visual candy there (:hover). In the block above, you can see the CSS3 way of adding a linear gradient, plus a few vendor-prefix versions conforming to a somewhat older syntax. Unfortunately, MSIE doesn’t support linear gradients in any CSS3-like way before IE10 (almost surprisingly, since IE9, even IE8, is pretty good in most other cases). Instead, in IE8+ you can use -ms-filter. But IE5.5-IE7 only supports the non-conforming unprefixed filter property. Hence, to add the gradient in old IEs, without making the CSS invalid, I put the unprefixed filter version in the IE7-specific stylesheet mentioned previously.
Similar to the main navbar, the pixlinks navbar was previously
<div class="logobar singleBorder" style="padding:8px;"> <strong>Plants:</strong> <a href="sommar.asp">Nature, summer</a>, <a href="vinter.asp">Nature, winter</a> | <strong>Animals:</strong> <a href="djur.asp">Mammals</a>, <a href="aves.asp">Birds</a>, <a href="reptiler.asp">Reptiles</a>, <a href="leddjur.asp">Arthropods and Molluscs</a> | <strong>Culture:</strong> <a href="nyc.asp">New York City (1/2</a>, <a href="nyc2.asp">New York City (2/2)</a> | <a href="portratt.asp">Portraits</a> | <a href="mathart.asp">Mathematical pictures</a> </div>
That is ugly! First, the separators, “,” and “|” are purely presentational (especially the latter). Second, the CSS class singleBorder was, as the name suggests, purely presentational, and hence it is an invalid class name (classes have nothing to do with styles). Third, inline CSS should only be used in the very rare cases when the style in some sense is very intimately connected with the element, maybe in a semi-semantic way. Fourth, according to the HTML5 semantics, <strong> is used to signify something important, like some particularly important passage in a warning text. It should definitely not be used to mark up some kind of ‘header’, like in this case. It’s plain incorrect. Today, the markup is much improved:
<ul class="two-level-nav"> <li> <b>Plants</b> <ul> <li><a href="sommar.asp">Nature, summer</a></li> <li><a href="vinter.asp">Nature, winter</a></li> </ul> </li> <li> <b>Animals</b> <ul> <li><a href="djur.asp">Mammals</a></li> <li><a href="aves.asp">Birds</a></li> <li><a href="reptiler.asp">Reptiles</a></li> <li><a href="leddjur.asp">Arthropods and Molluscs</a></li> </ul> </li> <li> <b>Culture</b> <ul> <li><a href="nyc.asp">New York City (1/2)</a></li> <li><a href="nyc2.asp">New York City (2/2)</a></li> </ul> </li> <li><a href="portratt.asp">Portraits</a></li> <li><a href="mathart.asp">Mathmematical pictures</a></li> </ul>
two-level-nav is a site-wide new class that can be used for two-level navigational lists, like this one. Notice that the class describes the semantics of the UL; it is not purely presentational like the ugly old singleBorder. I’d like a list header tag here, but <b> is fine according to the HTML5 semantics. The corresponding style is
/* Two-level nav */
ul.two-level-nav, ul.two-level-nav ul, ul.two-level-nav li { padding: 0; margin-left: 0; margin-right: 0; } ul.two-level-nav > li, ul.two-level-nav > li > ul { display: inline-block; } ul.two-level-nav > li > ul > li { display: inline; } ul.two-level-nav li { list-style-type: none; } ul.two-level-nav { background: #AEAD71; color: black; padding: 4px; } ul.two-level-nav > li { background: #CFCFAC; margin: 0px 0px; padding: 4px 8px; transition: background 250ms; } ul.two-level-nav > li:hover { background: white; } ul.two-level-nav b:after { content: ":"; } ul.two-level-nav ul li:not(:last-of-type):after { content: ","; }
One downside of this approach is that the last selector is very fancy, so the commas will disappear already in IE8. Of course, I could have used a simple ul.two-level-nav ul li + ul.two-level-nav ul li:before selector to add a comma followed by a space (this also requires some additional changes (why?)), but that appears somewhat less elegant. Since the loss of the commas isn’t that terrible, I chose elegant code before perfect backwards compatibility in this case. Also notice the nice CSS3 transition.
Turning to the main contents of the web pages, I follow strictly the HTML5 semantics, as described in the previous article. In practice, this means that quite a few <em> has been changed to more suitable elements. Yes, unfortunately, I used the stress emphasis element as a generic italics element, which is a semantic nightmare (almost, at least). Now I strictly use <em> only for stress emphasis, I use <dfn> for defining instances of phrases, <cite> for titles (of books, films, …), and <i> for phrases in a foreign language (together with the lang attribute, of course).
I actually believe that my sites are far better than most on the web today when it comes to semantics.
Further, I have been very careful to markup the (human) language of text. My site is bilingual (Swedish and English). The lang attribute is always set on the <html> element to the main language of the page. I also set the language explicitly on articles (<div class="article" lang="en">), sample grammar boxes, etc., explicitly. Then I use CSS content to add an English flag every time an English article appears on a Swedish page, and vice versa. For example, an article may look like
This article is found on my Swedish site, so an English flag will appear in the article’s header, because the article is in English. But the metadata names are in Swedish, because the article is served on the Swedish site. But the metadata is in the header, which is in the article, so the metadata needs to set the language to “sv” explicitly.
Notice that I think in HTML5 terms: Articles and headers.
I am also very careful to set the language correctly even on very small phrases in a foreign language, like in
<p>Jag påverkas också oerhört starkt av vissa filmer. Till exempel såg jag <cite lang="en">Titanic</cite> förra året. Efter filmen vaknade jag mitt i natten, och kände en förtvivlad sorgsenhet. Det var som att all lycka och glädje i världen sjönk med Titanic, och allt som återstod i min värld var tomhet. Ännu värre var <cite lang="en">The Phantom of the Opera</cite> (2004). Det är en alldeles underbar film, dels för musiken och scenerna, men också för filmens oerhörda (psykologiska) verklighet.
Being careful with the language, I suppose, is very important for screen readers.
Naturally, there are quite a few hyperlinks on my English site to my Swedish site, and in the opposite direction. If following a hyperlink will change the webpage language, this is indicated visually:
Now, return for a while to the article headers. Notice that I use description lists to mark up metadata name–value pairs, as is semantically rich. This is also new: Previously I used (oh, horror) <strong> and <br/> with plain text in a paragraph. Today I use the semantically-named class metadata when a description list is used as a metadata list. The CSS is
Let me end this article by giving a more fancy example of CSS content: I do write quite a lot about Swedish grammar on my site, and thus I need textboxes that exemplify both correct and incorrect written text. The markup might look like
<div class="correct-language"> <p>Vi kommer till tre städer: Stockholm, Linköping och Malmö.</p> </div>
Of course, I strictly make sure that the type of textbox (like correct or incorrect language) is made clear even with no stylesheet is applied.
The separation of presentational information (style) from markup has allowed me to serve a number of alternate stylesheets the user can choose from. I will talk more about that in a few days.
To try some of my new knowledge in practice, I wrote a primitive desktop calculator that woks in any modern browser (IE10, Chrome, Firefox, Safari, Opera, ...).
Generally, I love HTML5, CSS, SVG, and XML. Regarding HTML5, I am particularly fond of the new semantic elements (<header>, <footer>, <nav>, <main>, <article>, <section>, <aside>, and <figure>), the clarified semantics of old elements (such as <em>, <strong>, <i>, <b>, <cite>, and <dl>), the new <audio> and <video> elements, microdata, and the new form capabilities, just to mention a few of my personal favourites.
I am very fascinated by the power of XML, and – in particular – the power of XSL(T).
I have used my new knowledge to improve my own websites; now, almost all of my web pages are conforming XHTML 1.0 documents (and any exception is well-motivated and will vanish as soon as I upgrade to the HTML5 doctype). I have also redesigned the pages to be more semantic, and to separate content and style perfectly, where possible (and most often it is possible). In addition, I have added quite a lot of visual improvements using CSS, particularly using :before and :after, which will be visible in any modern browser, even including IE8+. When it comes to text-level semantics, I strictly follow the new HTML5 rules:
<em> is used for stress emphasis, and is usually rendered in italics. The use of <em> alters (or clarifies) the intended meaning of the sentence, usually by stressing some particular word in it (as opposed to some other word in it). It must not be used for anything other than this kind of emphasis.
<strong> is used to highlight an important part of a sentence, like the text ‘warning’, or a particularly important-to-notice word or passage in a warning text. The contents is usually rendered in boldface. The use of <strong> does not affect the meaning of the sentence (like <em> does). <strong> must not be used for any other reason than marking its contents as extra important.
<i> is used to contain a span of text in “an alternate voice or mood”, or otherwise “offset from the normal prose in a manner indicating a different quality of text” [quoted from the W3C spec]. Example applications include taxonomic designations and idiomatic phrases from languages different from the surrounding text’s main language. The default rendering is in italics. It is good practice to combine the element with a class attribute, unless (possibly) the current use of <i> is exceptional in the document. Of course, text in a different language should also be indicated using the lang attribute.
<b>, typically rendered in boldface, is used to highlight a span of text in order to draw the reader’s attention to it. For instance, one can use this element to highlight ‘keywords’ (in some sense and context) or to mark up a piece of text that could be considered a ‘heading’ or ‘lead’ of a paragraph. This element does not change the meaning of the text, nor does it indicate importance. One might use a class attribute to specify the particular semantics of an instance of this tag, which should only be used as a ‘last resort’ when no other, more specific, element is appropriate (like a heading, <em>, <strong>, or <dfn>).
<cite> is used to mark up a title of a book, article, magazine, newspaper, film, TV show, play, musical, sculpture, or some other named piece of art or work. The element is typically rendered in italics. As usual, if the contents of the element is in a different language, this should be specified using the lang attribute.
<dfn> is used to mark up the defining instance of a phrase in a document. The element is typically rendered in italics.
<mark> is used to highlight (e.g. using a yellow background colour) a part of a text quoted from a different source.
<var> (typical rendering: italics), <samp> (typical rendering: monospaced font), and <kbd> (typical rendering: monospaced font) are used for variables or placeholders, sample computer output, and user input (to a computer), respectively. The spec defines specific nesting semantics for the two last elements. In particular, a <kbd> element inside another <kbd> element represents a discrete key being part of the user input marked up by the outer element, like <kbd><kbd>Ctrl</kbd>+<kbd>Shift</kbd>+<kbd>Space</kbd></kbd>.
<abbr> is used to mark up abbreviations, including acronyms. The title attribute has special semantics for this element: it specifies the expanded form of the abbreviation. Again, it is important to specify the language correctly both for the attributes and for the text contents of the element. It is rather common, especially in non-English text, for abbreviations (that is, the text contents of the <abbr> element) to be pronounced using the text’s main language, while the expanded form of the abbreviation (that is, the title attribute of the <abbr> element) should be pronounced in English. Since the lang attribute specifies the language both of attributes and of the contents of the element, you need to use a <span> element with the appropriate lang attribute to enclose the text content of the <abbr> element, as in this example.
In addition, I try to use the description list (<dl>) every time I need to mark up any kind of name–value pairs (in a broad sense), including definition lists, metadata name–value pairs, and FAQs. However, for practical purposes, it would be good if the <di> tag from XHTML 2 was reinstalled (see my comment at html5doctor.com).
I would also like to replace <div id="header"> with <header>, and similarly for the other new semantic div-like elements. I believe this will fail in Internet Explorer 5.0 (even with the JavaScript trick), a browser that today is perfectly able to render my sites in a primitive but readable fashion. Hence, by using the new HTML5 semantic elements, I will raise the Internet Explorer minimum support level from 5.0 to 5.5, which I guess is acceptable, since Internet Explorer 5.5 can also be installed on Windows 95, an operating system I want to support. I would also like to replace the current navbar by a completely semantic one that perfectly separates content and style. I could do it like this, but this again would make the page harder to render for old IEs.
While improving my websites, I carefully monitor the rendering in old browsers. I have virtual machines running Windows 95, Windows XP, Windows Vista, and Windows 7, and the following versions of Internet Explorer:
Internet Explorer 3.0
Internet Explorer 4.0
Internet Explorer 5.0
Internet Explorer 5.5
Internet Explorer 6.0
Internet Explorer 7
Internet Explorer 8
Internet Explorer 9
Internet Explorer 10
In a few days, I will publish a small article giving all the details of the rendering of my sites in old versions of Internet Explorer.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}