
Rejbrand Text Editor 3.1.3: Statistics
As noted in the announcement of release 3.1.3 of Rejbrand Text Editor, the new version has an improved file statistics feature that compiles a list of the unique words in the text.
In this article, I’ll be discussing the behaviour and implementation of this feature, for the sake of both documentation and academic interest.
The goal
Writing a computer program that counts or extracts the words in a given text might seem like a very simple task, and to some extent, it is. Every programmer can write a rudimentary word counter or word extractor in a minute or two, and it will work pretty well in most cases.
But if you want it to produce the most desirable output in every possible case (which might even include different human languages), you’ll soon find out there are numerous subtleties involved. Eventually you’ll find out that writing an algorithm that works for all input is impossible, at least without relying on human-language dictionaries. Hence, the task is to create an algorithm that works well in most cases.
The basics
If a computer science teacher were to ask her students to write an algorithm in plain C or Pascal that counts the number of words in a text, I suppose most of the students would base their algorithm on the same general idea. They would iterate over the text, one character at a time, and keep track of when they enter and leave a word based solely on the current state (inside a word or not) and the nature of the current character. In Pascal-like pseudocode,
function WordCount(const AText: string): Integer;
var
InWord: Boolean;
i: Integer;
begin
Result := 0;
InWord := False;
for i := 1 to Length(AText) do
if InWord then
begin
if IsWordSep(AText[i]) then
InWord := False;
end
else
begin
if not IsWordSep(AText[i]) then
begin
InWord := True;
Inc(Result);
end;
end;
end;
However, I imagine they would not all use the same test for the “nature” of the current character. In other words, they would define IsWordSep differently. Some would likely test for whitespace, while others would test for non-letters. Specifically, this amounts to defining IsWordSep(chr) as IsWhitespace(chr) and not IsLetter(chr), respectively.
For very simple input, like “I love cats!”, these choices give the same result. But if you attempt anything more involved, you will notice some differences:
| Whitespace | Letter | |
|---|---|---|
| I didn’t do it. | 4 | 5 |
| He’s a crime-fighting canine. | 4 | 6 |
| Use a word processor (e.g. Microsoft Word). | 7 | 8 |
| Han äter mycket grönsaker. (He eats a lot of vegetables.) | 4 | 4 or 5 |
| CD-brännare (CD burner) | 1 | 2 or 3 |
Indeed, the letter-based approach sees the apostrophe (and its typographical version, the right single quotation mark), hyphen, and period as word separators. Furthermore, if the “is a letter” test is based on the naïve assumption that the only letters are the ASCII characters A to Z and a to z, the algorithm also fails on input containing words with non-English letters. (But I suspect that most modern programming languages and libraries offer a Unicode-based “is letter” function.)
Notice that IsWhitespace(chr) implies not IsLetter(chr), so the letter-based approach will always yield more numerous but shorter word candidates. The problem is that it goes too far: indeed, as we have seen, some words contain non-letter characters such as apostrophes, hyphens, and periods.
It should be clear that the whitespace-based approach is to be preferred, especially since we want to extend the algorithm from a simple word counter to a word extractor, and we certainly don’t want it to return “didn”, “t”, “s”, “e”, and “g” as words in these examples.
Word extraction
Turning a word counter into a word extractor might seem entirely trivial, but there are still a few things to watch out for. Consider the following example:
I have one dog, two rats (!), and three birds (all parakeets).
The whitespace-based approach will extract twelve suggested words from this text:
- I
- have
- one
- dog,
- two
- rats
- (!),
- and
- three
- birds
- (all
- parakeets).
Here we observe an issue: punctuation is attached to the suggested words. We need to trim the suggested words, that is, to remove leading and trailing punctuation. Doing so, we end up with
- I
- have
- one
- dog
- two
- rats
- and
- three
- birds
- all
- parakeets
discarding all empty words that are produced in the process.
Ironically, the letter-based approach would have saved us from this extra step, but we have already ruled out that approach, since it fails on words containing apostrophes, hyphens, periods, etc.
Notice that we only trim leading and trailing punctuation from the suggested words, and no other non-letters. For instance, we do want “The precursor is 7-dehydrocholesterol.” to produce
- The
- precursor
- is
- 7-dehydrocholesterol
This is perhaps even more important in Swedish, for instance, where we have words like “50-öring” (50-öre coin) and “20-åring” (20-year-old (n.)).
The RTE implementation
The word extractor in Rejbrand Text Editor 3.1.3 is based on the approach outlined above: it first splits the text into suggested words based on a list of word-separating characters (mainly whitespace), and then removes leading and trailing punctuation from the word candidates. Additionally, it verifies that the final suggested word contains at least a single Unicode letter, so that “I have 539 books ☺.” will yield only “I”, “have”, and “books”.
Word separators
By default the list of word-separating characters include all Unicode whitespace, “/” (U+002F: SOLIDUS), the em dash “—” (U+2014: EM DASH), “<” (U+003C: LESS-THAN SIGN), “>” (U+003E: GREATER-THAN SIGN), and “=” (U+003D: EQUALS SIGN). Hence, RTE adds a few non-whitespace characters to the list of word separators. The idea is to include only characters that very seldom are part of words (that is, they don’t do any harm being on the list), but occasionally serve as sole word separators (that is, they are needed on the list).
Thus, I obviously don’t include the apostrophe (or the right single quotation mark), hyphen, and period. But I also refrain from including characters like the exclamation mark, the question mark, colon, semicolon, and parentheses.
Parentheses
For instance, consider the case of parentheses. They do occur within words:
dog(s), (un)healthy, (X)HTML
(Thus, parentheses would do harm on the list.)
Furthermore, when they are not part of words, they are nearly always adjacent to whitespace:
Tony Blair (born 1953) is a former prime minister of the UK.
The cat played with his toy (the one I bought yesterday).
(Thus, they are nearly never sole word separators, so they are nearly never needed on the list; in this case, whitespace will split the text into the appropriate words.)
Colon
Similarly, the colon is used in Swedish to connect a suffix to an initialism, digit, letter, or code:
SVT:s webbplats, 5:a, 7:or, bokstaven T:s seriff, CO2:s egenskaper
In some special cases, it is also used to mark contractions (S:t). And, just like the parentheses, when it doesn’t belong inside a word, it is nearly always adjacent to whitespace:
I have three cars: one Volvo, one Peugeot, and one BMW.
The idea is simple: just do what you originally planned to do.
Relational operators
The equals sign (=), the less than sign (<), and the greater than sign (>) are very rarely parts of words, but they do sometimes act as sole word separators, at least in semi-technical contexts. Hence, it arguably makes sense to add these characters to the list of word separators.
Solidus
The most difficult decisions to be made are those regarding solidus, the en dash, and the em dash.
I chose to include solidus (/) as a word separator because it frequently acts as a sole word separator, often semantically equivalent to an inclusive or exclusive or or a mathematical division:
Then you must immediately inform him/her.
Use bold and/or italic to highlight the word.
Do you know any actors/performers/singers?
It can record more than 560 actions/second.
Still, in some cases the solidus is a part of a word: RTE will incorrectly parse “s/he” as “s” and “he”. Also, it is questionable whether or not it is desirable to parse “km/h” as “km” and “h”.
Dashes
Turning to dashes, I chose not to include the en dash as a word separator, because this character sometimes occurs inside words, especially in Swedish:
3–2-segern (the 3–2 victory)
mor–dotter-relation (mother–daughter relationship)
Sverige–Danmark-matchen (the Sweden–Denmark game)
natrium–kaliumpumpen (the sodium–potassium pump)
renin–angiotensinsystemet (the renin–angiotensin system)
It would indeed be unfortunate if this were parsed as “2-segern”, “dotter-relation”, “Danmark-matchen”, etc.
And, when it is not used within words, the en dash usually has whitespace next to it:
Many people – even some of his own supporters – now began questioning his policy.
In some cases, it doesn’t matter if it is a word separator or not, since the dash is surrounded by numbers:
pages 20–34
ages 7–10
2010–15
13:00–15:00
But in other cases, the RTE behaviour is potentially unwanted:
mother–daughter relationship
the Sweden–Denmark game
the sodium–potassium pump
the renin–angiotensin system
the New York–Stockholm flight
The em dash is not used in Swedish. In English, it is often used like the en dash to introduce a break in a sentence (often like a colon) or (paired) to set off a parenthetical statement (like a pair of commas or parentheses), but typically without the surrounding whitespace. In addition, it is very rarely used within words. Therefore, it should be considered a word separator.
Many people—even some of his own supporters—now began questioning his policy.
Source-code mode
The remarks made so far applies to human-language texts. For source code, the described approach fails rather badly. For instance, if you try to extract the words of
Box.X := (Self.Width - Box.Width) / 2;
RedrawObject(Frame, True);
RedrawObject(Box, True);
you likely expect to get the individual identifiers (“Box”, “X”, “Self”, “Width”, “RedrawObject”, “Frame”, “True”), and not things like “Box.X”, “Self.Width”, “Box.Width”, “RedrawObject(Frame”, and “RedrawObject(Box”.
Essentially, in source code, you’d want the programming language’s operators (and other kinds of tokens that separate identifiers) to act as word separators. In Rejbrand Text Editor, you can enable such a “source-code mode” in the statistics dialog box. This will add the following characters to the list of word separators:
.,;:-+*/=()[]{}<>|\%&@~!?This certainly makes a huge difference in source code. Instead of getting a hundred different “words” beginning with “Length(”, you get a single word “Length” (with a high count).
The following example shows the effect of source-code mode in an actual Pascal file. Without source-code mode, there are many unwanted combinations of identifiers, rendering the list nearly useless:
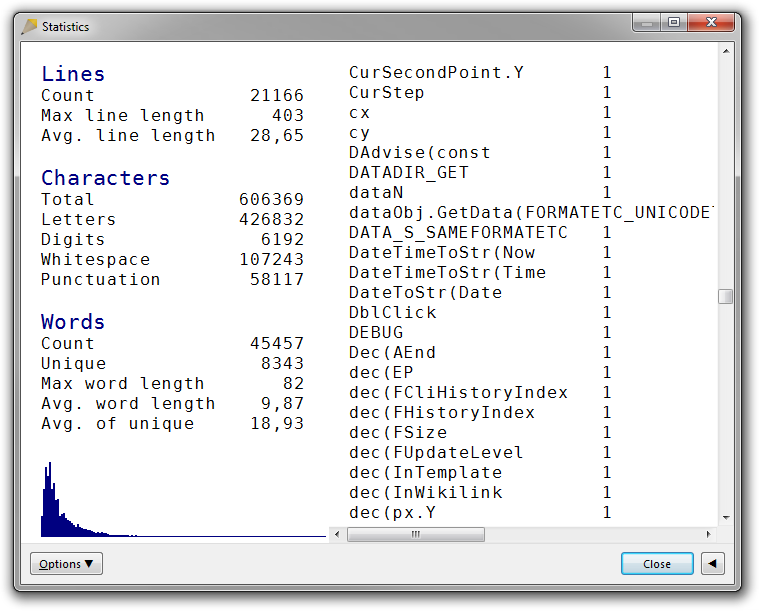
On the other hand, with source-code mode enabled, the word list very neatly lists all source code keywords, identifiers, textual operators, and string literal words.
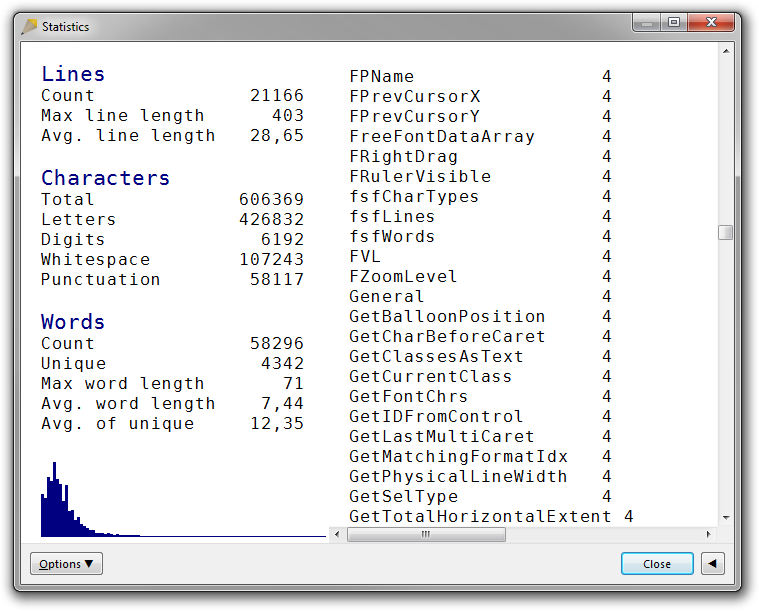
Notice that the additional word separators don’t include the apostrophe or the right single quotation mark, so the algorithm will still handle string literals containing English contractions well. Typically, these characters aren’t necessary as word separators even in source code, since in source code they are typically next to parentheses, commas, colons, semicolons, or equal signs, if not whitespace.
In fact, source-code mode often works well enough in human text to be useful there too, should you need to split words on hyphens, say.
Word-separation issues
No matter how carefully you design your algorithm, you will not be able to make it work all of the time, at least not without using dictionaries.
Words containing spaces
A Swedish “Harry Potter fan” could be called a “Harry Potter-fantast”. While it makes sense to say that “Harry Potter fan” consists of three words (“Harry”, “Potter”, and “fan”), it is less ideal to claim that “Harry Potter-fantast” consists of the two words “Harry” and “Potter-fantast”. The problem is that “Harry Potter-fantast” is a single compound word constructed from “Harry Potter” and “fantast”, but the first word of the compound, “Harry Potter”, contains a space.
Similarly, “Datorn är Windows 7-kompatibel” (“The computer is Windows 7 compatible”) will produce the word “7-kompatibel”, which makes no sense at all.
And in English, you might want to consider “a priori” a single word. Again, not possible.
Words ending with a period
Some words end with a period, such as English “e.g.”, “i.e.”, “etc.” and Swedish “t.ex.”, “bl.a.”, “o.s.v.”. These periods will unfortunately be lost. You might be tempted to attempt to guess whether the period is part of the word or not based on the surrounding text, but will find that to be a very difficult problem in general (really, it is not doable).
The best way to fix this issue is likely to give the algorithm access to a list of common words ending with period. RTE doesn’t use such a list.
Words containing parentheses
As noted above, some words contain parentheses:
colo(u)r, dog(s), (un)healthy, (X)HTML
Unfortunately, leading and trailing parentheses will be lost, leaving garbage behind: “dog(s”, “un)healthy”, “X)HTML”. This would be possible to fix by an addition to the algorithm:
When a leading or trailing parenthesis is to be removed, check if (1) the next character is not punctuation and (2) removing the parenthesis would leave a word with unbalanced parentheses. If both conditions are met, keep the parenthesis.
I almost decided to implement that addition, but decided not to. Indeed, that would be an example of a non-trivial amount of added logic that would improve the algorithm’s output only for a tiny fraction of all possible input. And maybe there are even words that are supposed to contain unbalanced parentheses? Of course, they might also end up next to a sentence-level parenthesis.
Still, I do suspect the benefits of such an addition would outweigh the potential problems, so I am a bit tempted to implement it in a future release.
Character case issues
Rejbrand Text Editor compiles a list of the unique words of the text, together with the frequency of each word. Hence, the algorithm must be able to compare words for equality. Typically, you do want this comparison to be made in a case-insensitive manner. For instance, if a text contains five instances of “cats” and two instances of “Cats” (the first word of a new sentence), you want the list to contain the word “cats” with a count of 7.
By default, Rejbrand Text Editor does compare words in such a case-insensitive manner, but the statistics dialog box contains an option to enable case-sensitive comparisons.
Consider the following example:
Emma came here at noon. She immediately started playing with the dogs.
The dogs really enjoyed it – many of them are pretty bored when she isn’t here.
Many hours later, she went home again.
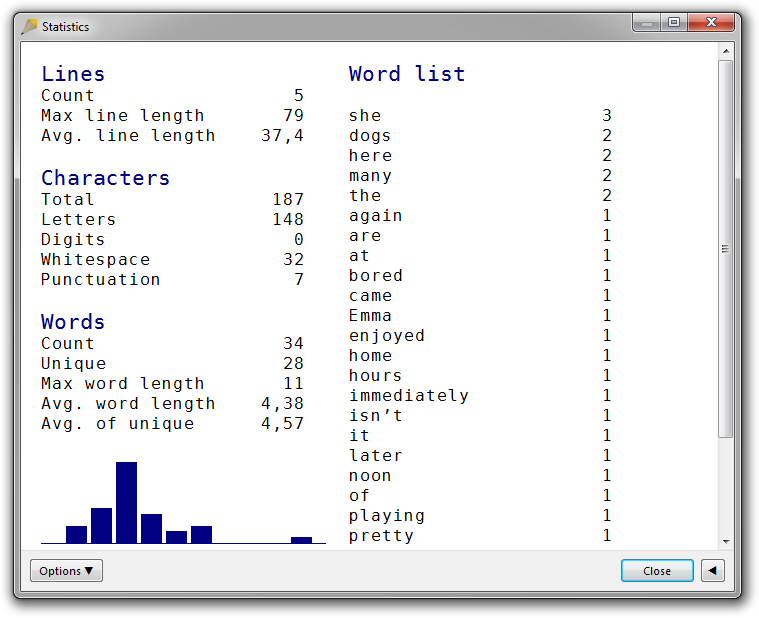
Notice that “she”, “the”, and “many” are compared case-insensitively. More importantly, notice that they are presented in their lower-case forms in the word list, while “Emma” is capitalized.
This is not made possible thanks to a dictionary of known names, but to a very simple rule: If a word is present multiple times in the text in different character-case versions and an all-lower-case version is present, then the all-lower-case version will be displayed in the list. Otherwise, the version of the first instance of the word will be used.
This way it is guaranteed that every word displayed in the list is in a form actually present in the file, and a best effort is made to determine if the word has to be capitalized or not. But of course, the approach isn’t perfect: remove the middle sentence and you’ll find “Many” capitalized in the list.
Options
The Options button in the statistics dialog box contains options that affect the computation behind the statistics and the presentation of the computed data. We have already discussed the source-code mode and case sensitivity.
To illustrate the statistics feature in action, I downloaded a few books from Project Gutenberg. Some of these use unspaced double hyphens instead of the en or em dash as sentence-level punctuation, so either you have to replace all such double-dashes with spaced en dash or unspaced em dash, or you have to enable source-code mode.
Graph options
By default, the word-length distribution graph displays the length distribution of all words in the text. Hence, stop words like “a”, “the”, “and” will make the graph heavy on the left side. If you enable the Graph unique words option, you will instead be presented with the length distribution of the unique words of the text, typically making the graph more bell-shaped. (Often source-code mode helps as well.)
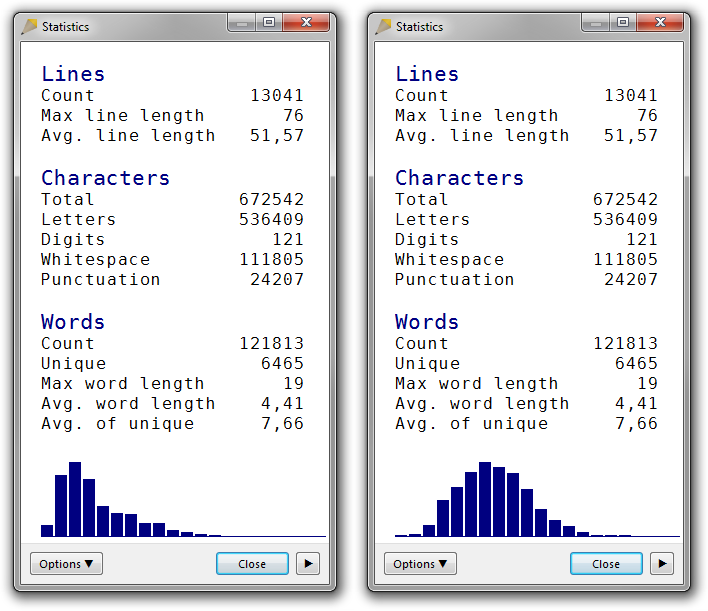
By the way, the diagram is interactive. You can click any bar to display the data behind it.
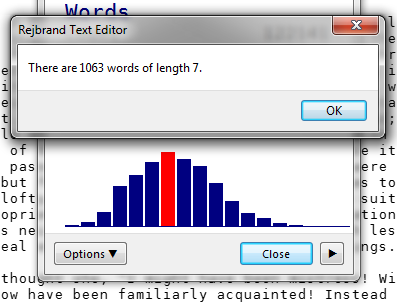
Sorting
The word list can be sorted in different ways. By default, the list is sorted by frequency:
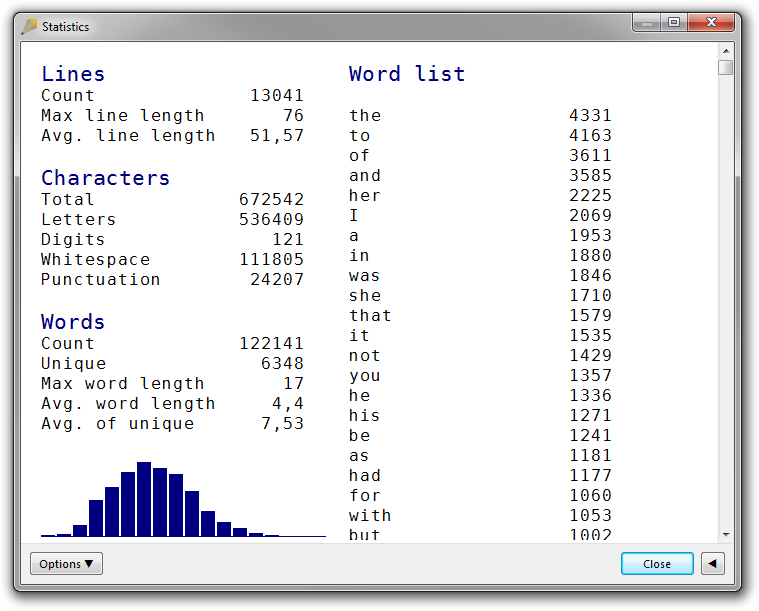
(Pride and Prejudice by Jane Austen)
It can also be sorted alphabetically, case insensitively:
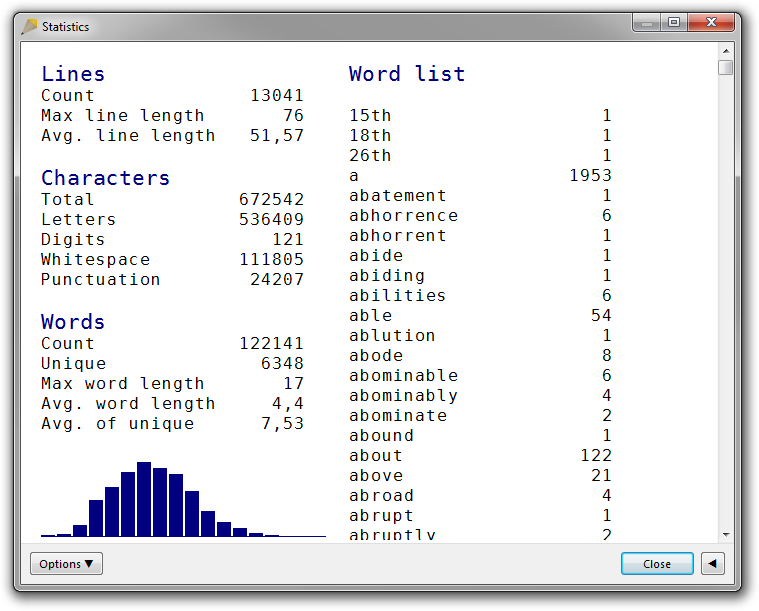
If you sort it alphabetically but case sensitively, you almost get a list of all proper nouns at the top:
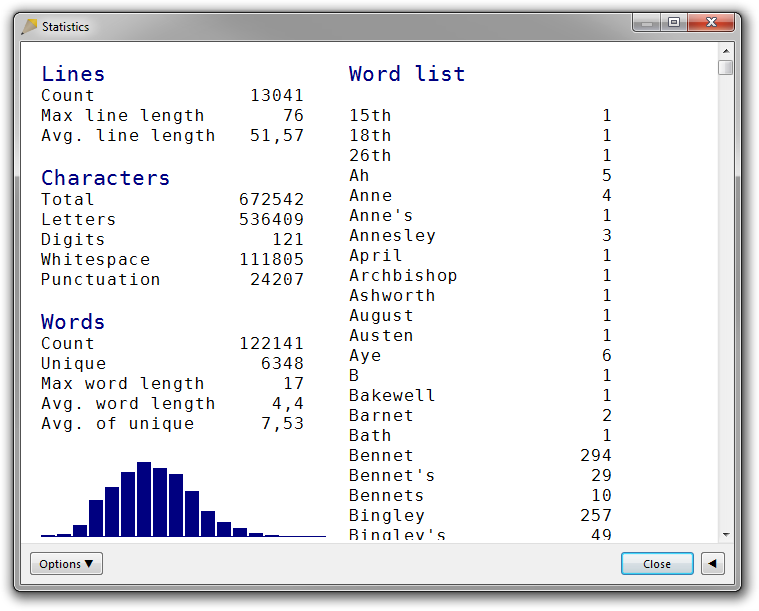
If you sort by word length, you are likely to get hyphenated words such as attributive compound modifiers at the end:
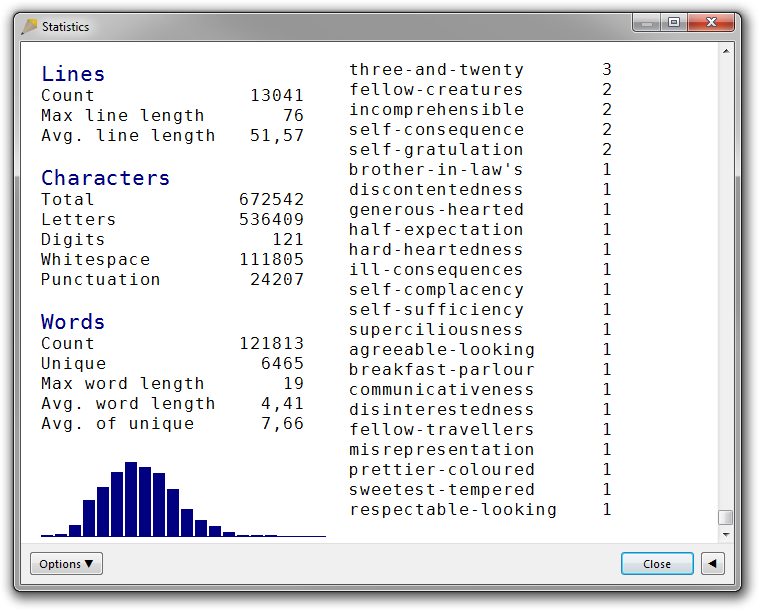
Enabling source-code mode, you get rid of those:
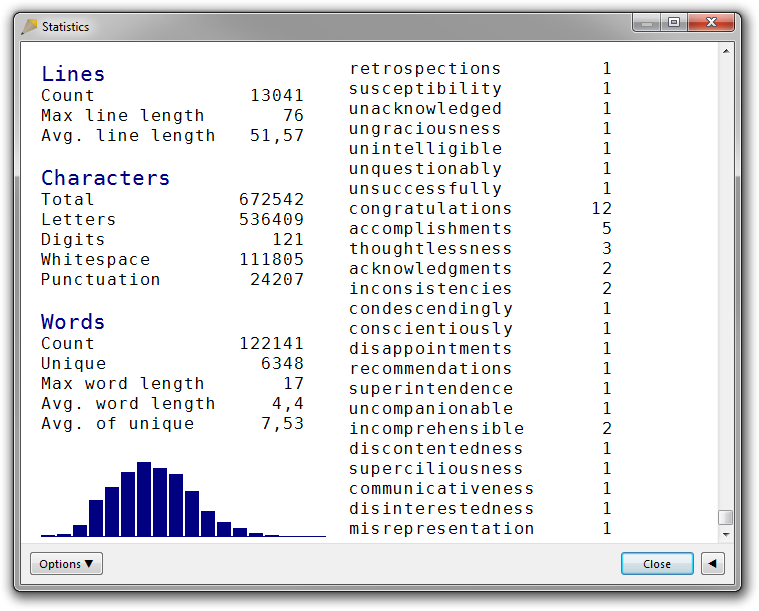
Sometimes, you find something interesting at the bottom:
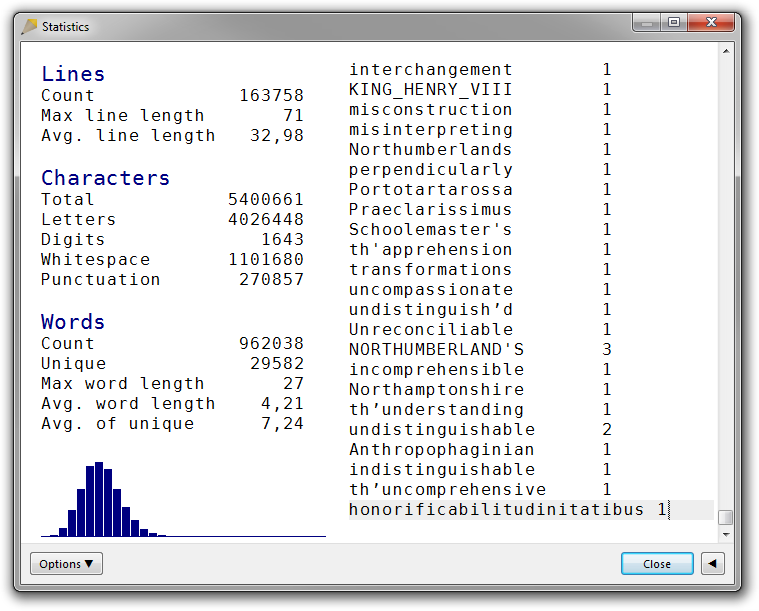
(The Complete Works of William Shakespeare)