
Rejbrand Text Editor 3.1: Text transformation
Last time, we had a look at some of Rejbrand Text Editor’s features related to Unicode characters. This time, we will focus on some of the text transformation features of the software.
Of course, all text editors have features for “transforming” (or “editing”) text files and almost all Windows editors offer standard keyboard (and mouse) navigation and input (character keys, Backspace, Delete, arrow keys, Home, End, Ctrl+something, selections, ...) and the standard interface to the operating system clipboard, and we will not say anything about these bare-minimum features. Instead, we will concentrate on the text-transformation features that are not found in every editor, and certainly not in simple editors like Notepad. We proceed by giving examples of actual text-transformation scenarios and their possible solutions using Rejbrand Text Editor.
Paste as
Suppose you have a few paragraphs of text in Microsoft Word and you need to obtain their HTML representation. This amounts to surrounding each paragraph by <p> and </p>. Rejbrand Text Editor can do this for you, using the Edit/Paste as feature:
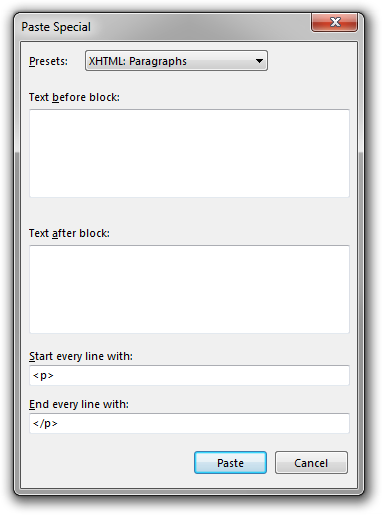
In one of my regular workflows, I also need the hypertext code to be single line. Hence, I replace all line breaks with the empty string in the pasted text:
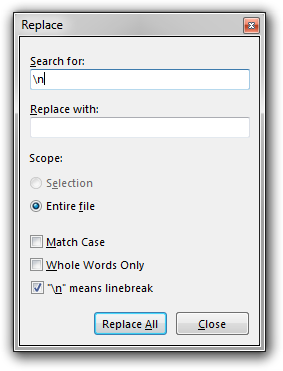
(This might cause a very long line to appear. To navigate this, I personally appreciate the scrolling mode entered by holding down the Alt key. In this mode, I can pan the document by dragging it using the mouse. More generally, in this mode all actions that normally would move the caret now scrolls the document, such as the arrow keys and dragging the mouse. Instead of holding down the Alt key, you can enter this mode by toggling the Scroll Lock key to the “on” state.)
Multiple carets
Suppose you have the following HTML snippet and need to add the directory Docs to all hyperlinks:
<ul>
<li><a href="limits.html">Limits</a></li>
<li><a href="antiderivatives.html">Antiderivatives</a></li>
<li><a href="derivatives.html">Derivatives</a></li>
<li><a href="integrals.html">Integrals</a></li>
<li><a href="odes.html">Differential equations</a></li>
</ul>
Of course, you could select the block and replace all instances of href=" with href="docs/, but it is easier with multiple caret input. Simply put the caret after href=" on the last line and press Ctrl+Up four times (or, put the caret on the first line and press Ctrl+Down four times). Then type docs/ and press Esc to exit multiple caret mode:
![]()
In multi-caret mode, which you can also enter by pressing Ctrl+M, you may add new carets anywhere by clicking using the mouse. Hence, the carets need not be above/below each other. You may even have multiple carets on a single line:
![]()
Also notice that the second and the third list items (“Antiderivatives” and “Derivatives”, respectively) should be swapped, because you must learn about derivatives before you can learn about antiderivatives. To do so, put the caret on the second line and press Shift+Ctrl+Down or on the third line and press Shift+Ctrl+Up.
Overwrite mode
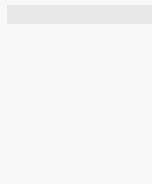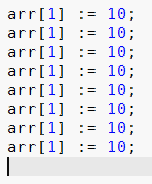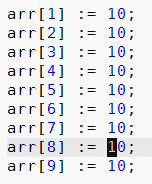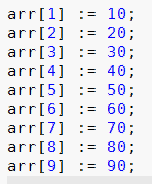
Although overwrite mode is a feature found in most text editors (but not Notepad as of Windows 7), it is probably not as well known as it should be. Because of this, I want to give an example of when it can be useful. Suppose you want to enter this source code:
arr[1] := 10;
arr[2] := 20;
arr[3] := 30;
arr[4] := 40;
arr[5] := 50;
arr[6] := 60;
arr[7] := 70;
arr[8] := 80;
arr[9] := 90;
The easiest way to do this is likely to write the first line, copy it eight times, and then update the numbers using overwrite mode, which you enter by pressing the Insert key:
Filter lines and Truncate lines
Consider the following HTML table:
<table>
<caption>Greek letters</caption>
<tr>
<th>Code</th>
<th>Character</th>
<th>Description</th>
</tr>
<tr>
<td>\Alpha</td>
<td>Α</td>
<td>U+0391: GREEK CAPITAL LETTER ALPHA</td>
</tr>
<tr>
<td>\alpha</td>
<td>α</td>
<td>U+03B1: GREEK SMALL LETTER ALPHA</td>
</tr>
<tr>
<td>\Beta</td>
<td>Β</td>
<td>U+0392: GREEK CAPITAL LETTER BETA</td>
</tr>
<tr>
<td>\beta</td>
<td>β</td>
<td>U+03B2: GREEK SMALL LETTER BETA</td>
</tr>
<tr>
<td>\Gamma</td>
<td>Γ</td>
<td>U+0393: GREEK CAPITAL LETTER GAMMA</td>
</tr>
<tr>
<td>\gamma</td>
<td>γ</td>
<td>U+03B3: GREEK SMALL LETTER GAMMA</td>
</tr>
...
Given this table, we would like to extract the following list:
U+0391: GREEK CAPITAL LETTER ALPHA
U+03B1: GREEK SMALL LETTER ALPHA
U+0392: GREEK CAPITAL LETTER BETA
U+03B2: GREEK SMALL LETTER BETA
U+0393: GREEK CAPITAL LETTER GAMMA
U+03B3: GREEK SMALL LETTER GAMMA
...
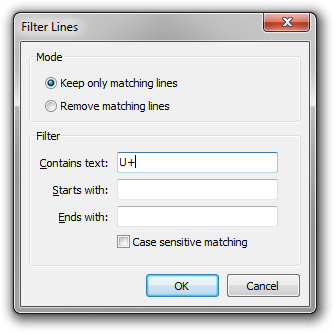
This is very easy using the Edit/Filter lines feature. Simply keep only lines containing the text “U+”:
This yields
<td>U+0391: GREEK CAPITAL LETTER ALPHA</td>
<td>U+03B1: GREEK SMALL LETTER ALPHA</td>
<td>U+0392: GREEK CAPITAL LETTER BETA</td>
<td>U+03B2: GREEK SMALL LETTER BETA</td>
<td>U+0393: GREEK CAPITAL LETTER GAMMA</td>
<td>U+03B3: GREEK SMALL LETTER GAMMA</td>
...
Now, search for <td> and replace with the empty string (Ctrl+R), and do the same for </td>. Finally, remove all leading whitespace (indentation) by selecting the block (if that is the entire file, by pressing Ctrl+A) and pressing Shift+Ctrl+Backspace. (Or, use Edit/Remove all indent.)
Now you see this:
U+0391: GREEK CAPITAL LETTER ALPHA
U+03B1: GREEK SMALL LETTER ALPHA
U+0392: GREEK CAPITAL LETTER BETA
U+03B2: GREEK SMALL LETTER BETA
U+0393: GREEK CAPITAL LETTER GAMMA
U+03B3: GREEK SMALL LETTER GAMMA
...
You suddenly realise that you only want the capital letters. Easy! Just filter the lines again, using “CAPITAL” as the text to filter for:
U+0391: GREEK CAPITAL LETTER ALPHA
U+0392: GREEK CAPITAL LETTER BETA
U+0393: GREEK CAPITAL LETTER GAMMA
...
If you only want the descriptions, not the codepoints, you can use the Edit/Truncate lines feature (screenshot). In this case, you may truncate at the first occurrence of the colon (“:”) from the beginning of the line, removing the colon itself. Make sure to perform a reverse truncation, so that the text after the colon is preserved, not the text before it. Then remove the leading whitespace as before:
{kind=link}
GREEK CAPITAL LETTER ALPHA
GREEK CAPITAL LETTER BETA
GREEK CAPITAL LETTER GAMMA
...
(In this very simple case, it would have been easier to truncate at the fixed column 9 or at the first occurrence of the space character. Then we wouldn’t have needed to remove the leading space characters. In a small list, we could also have used multiple carets and Backspace or a block selection (to select the “U+NNNN: ” block) and Delete or Backspace.)
Block paste etc.
Suppose you have this source code and need the same code but with all assignments reversed:
eFirstName.Text := FFirstName;
eLastName.Text := FLastName;
eTitle.Text := FTitle;
eCompany.Text := FCompany;
eHomeStreet.Text := FHomeStreet;
eHomePostalCode.Text := FHomePostalCode;
eHomeCountry.Text := FHomeCountry;
eHomePhone.Text := FHomePhone;
eWorkStreet.Text := FWorkStreet;
eWorkPostalCode.Text := FWorkPostalCode;
eWorkCountry.Text := FWorkCountry;
eWorkPhone.Text := FWorkPhone;
eCellphone.Text := FCellphone;
eHomeEmail.Text := FHomeEmail;
eWorkEmail.Text := FWorkEmail;
eWebsite.Text := FWebsite;
Here is one way:
Select the block of text and press Shift+Ctrl+T to put a copy of it in a new tab.
In the original tab, use Edit/Truncate lines to remove everything before (“reverse truncation”) the first space character from the end of the lines, including the space characters themselves. Then use Replace all to remove the semicolons:
FFirstName
FLastName
FTitle
FCompany
FHomeStreet
FHomePostalCode
FHomeCountry
FHomePhone
FWorkStreet
FWorkPostalCode
FWorkCountry
FWorkPhone
FCellphone
FHomeEmail
FWorkEmail
FWebsiteIn the new tab, use Edit/Truncate lines to remove everything after the first space character from the beginning of the lines, including the space characters themselves:
eFirstName.Text
eLastName.Text
eTitle.Text
eCompany.Text
eHomeStreet.Text
eHomePostalCode.Text
eHomeCountry.Text
eHomePhone.Text
eWorkStreet.Text
eWorkPostalCode.Text
eWorkCountry.Text
eWorkPhone.Text
eCellphone.Text
eHomeEmail.Text
eWorkEmail.Text
eWebsite.TextNow, in the original tab, use multiple carets to insert
:=at a fixed column to the right of the existing text on each line:FFirstName :=
FLastName :=
FTitle :=
FCompany :=
FHomeStreet :=
FHomePostalCode :=
FHomeCountry :=
FHomePhone :=
FWorkStreet :=
FWorkPostalCode :=
FWorkCountry :=
FWorkPhone :=
FCellphone :=
FHomeEmail :=
FWorkEmail :=
FWebsite :=Select all text (Ctrl+A) in the second tab and copy it to clipboard (Ctrl+C).
In the original tab, put the caret one space after the
:=on the first line and choose Edit/Block paste (Shift+Ctrl+V):FFirstName := eFirstName.Text
FLastName := eLastName.Text
FTitle := eTitle.Text
FCompany := eCompany.Text
FHomeStreet := eHomeStreet.Text
FHomePostalCode := eHomePostalCode.Text
FHomeCountry := eHomeCountry.Text
FHomePhone := eHomePhone.Text
FWorkStreet := eWorkStreet.Text
FWorkPostalCode := eWorkPostalCode.Text
FWorkCountry := eWorkCountry.Text
FWorkPhone := eWorkPhone.Text
FCellphone := eCellphone.Text
FHomeEmail := eHomeEmail.Text
FWorkEmail := eWorkEmail.Text
FWebsite := eWebsite.TextFinally, perform a Replace all operation to replace each linebreak with a semicolon plus a linebreak:
FFirstName := eFirstName.Text;
FLastName := eLastName.Text;
FTitle := eTitle.Text;
FCompany := eCompany.Text;
FHomeStreet := eHomeStreet.Text;
FHomePostalCode := eHomePostalCode.Text;
FHomeCountry := eHomeCountry.Text;
FHomePhone := eHomePhone.Text;
FWorkStreet := eWorkStreet.Text;
FWorkPostalCode := eWorkPostalCode.Text;
FWorkCountry := eWorkCountry.Text;
FWorkPhone := eWorkPhone.Text;
FCellphone := eCellphone.Text;
FHomeEmail := eHomeEmail.Text;
FWorkEmail := eWorkEmail.Text;
FWebsite := eWebsite.Text;If you want to get rid of the multiple spaces before the assignment operators (
:=), you can replace all “ ” (two spaces) with “ ” (single space) a few times (in this case, four times is enough). Since the Replace dialog remains open after each operation, you only need to press Enter a few times in a row after you have entered the search and replace strings.
Fill with character
A source code file might begin with the following multi-line comment:
{******************************************************************************}
{ }
{ Rejbrand Text Editor Control 3.1 }
{ }
{ Copyright © 2015-2018 Andreas Rejbrand }
{ }
{ https://english.rejbrand.se/ }
{ }
{******************************************************************************}Suppose you want to use this comment as a template for a new comment, similar but different, in a new source code file. Then you’d like to replace all text with new text. This is actually easy: Simply make a block selection (Ctrl-dragging the mouse or using Shift+Alt+Arrow keys etc.) of the interior of the comment, select Edit/Fill with character, and fill it with space:
